领域驱动设计与微服务
Oct 22 2020DRF的起手式
- CURD Boy的通常的工作模式
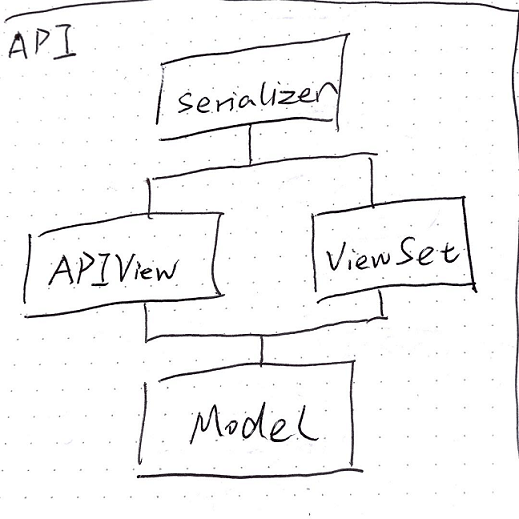
- 先设计Serializer还是先设计Model?
问题是什么
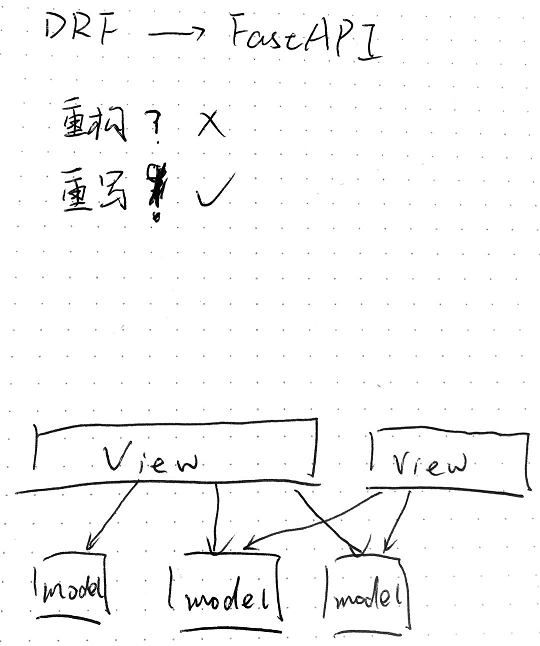
- 框架捆绑
- 写框架无关的代码
- 复杂的逻辑会陷入职责不清晰, 交叉依赖
- 抽象一层
面向对象
SOLID原则
| - | - | - |
|---|---|---|
| SRP | The Single Responsibility Principle | 单一责任原则 |
| OCP | The Open Closed Principle | 开放封闭原则 |
| LSP | The Liskov Substitution Principle | 里氏替换原则 |
| DIP | The Dependency Inversion Principle | 依赖倒置原则 |
| ISP | The Interface Segregation Principle | 接口分离原则 |
clean Architecture
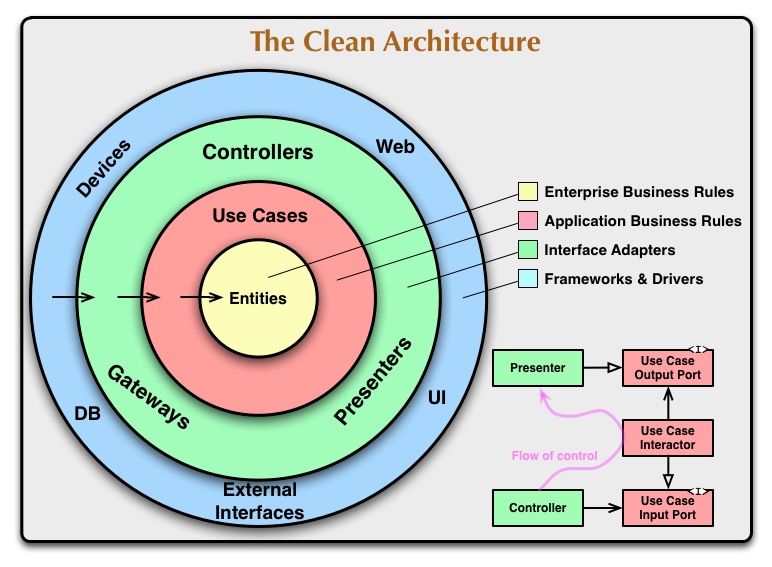
- 实体: 模型, 比如权限中心的一条策略就是一个实体, 它具有唯一的ID
- 模型不是分散的, 与存储无关, 避免交叉依赖
- 用例: 业务的使用规则, 实例在某种场景下的使用方式, 一段实体的使用逻辑
- 与api无关, 只与业务逻辑相关
- 对外暴露接口与适配器
- 隐藏用例与实体, 只对外暴露接口
- 框架, 驱动
- 对接接口, 实现适配器接口
- 从业务出发, 以业务逻辑为核心构建系统
- 灵活的使用外部依赖, 扩展方便
六边形架构
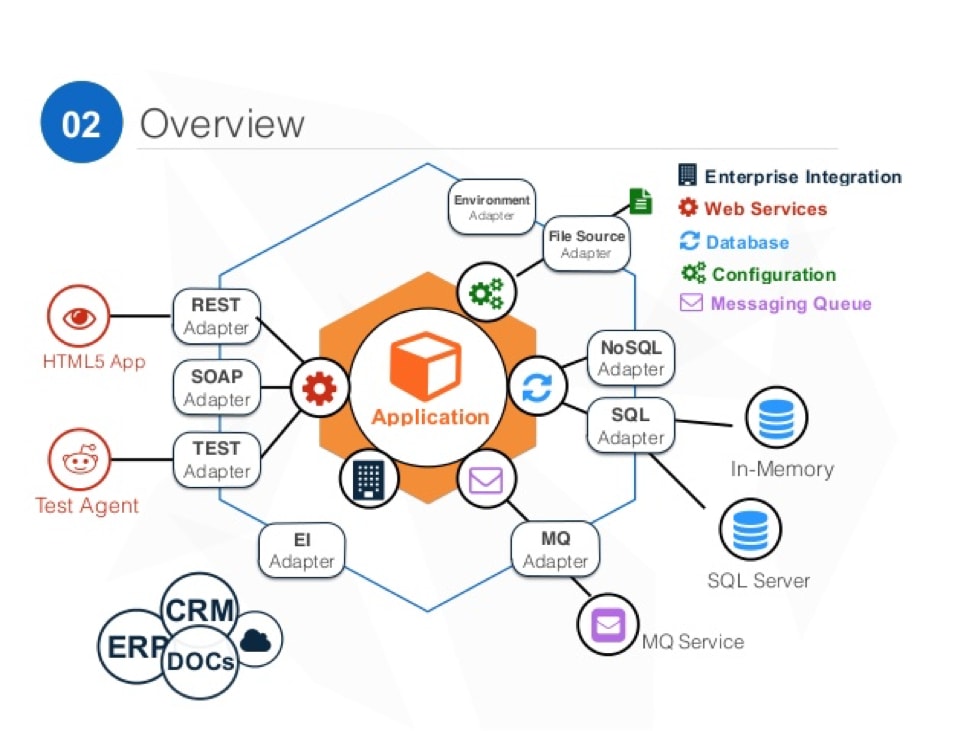
- 以业务为核心, 外部依赖全部做成适配器, 方便替换
领域驱动设计
为解决复杂的现实问题的一种设计模式, 将数据和行为封装在一起,并与现实世界中的业务对象相映射。各类具备明确的职责划分,将领域逻辑分散到领域对象中。
- 业务架构——根据业务需求设计业务模块及其关系
- 系统架构——设计系统和子系统的模块
- 技术架构——决定采用的技术及框架
DDD的核心诉求就是将业务架构映射到系统架构上,在响应业务变化调整业务架构时,也随之变化系统架构。
什么是领域
在互联网兴起之前, 传统的软件行业, 做的软件都是在解决现实中已经存在的问题, 软件的意义在于提示现实问题处理的效率, 比如电子商务, 现实中的商务模式只怎样运转的, 电子商务就是怎样运转的, 软件系统的意义在于大大提升了商务模式的运转的效率, 所以要设计一个好的软件系统, 先要有足够的领域知识, 以现实中出现的问题为基础, 构建领域的模型
已订单模型为例, 同样是订单, 对于购买客户展示的订单与对商户展示的订单信息就不一样, 操作也不一样, 这就需要对模型进行域的划分, 分别分为客户域与商户域
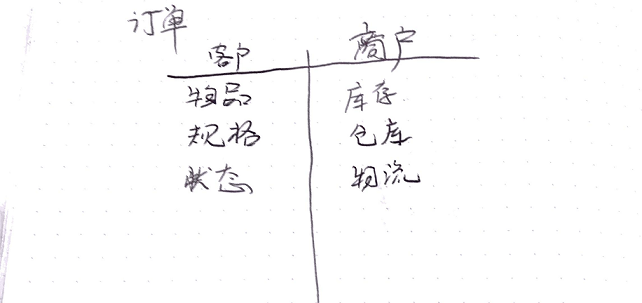
领域语言
定义术语, 识别出领域内的用例主谓宾, 主语: 实体, 谓语: 用例, 宾语: 值对象, 比如在权限中心, 管理员对用户授权了xx权限
领域模型 – Entry与ValueObject
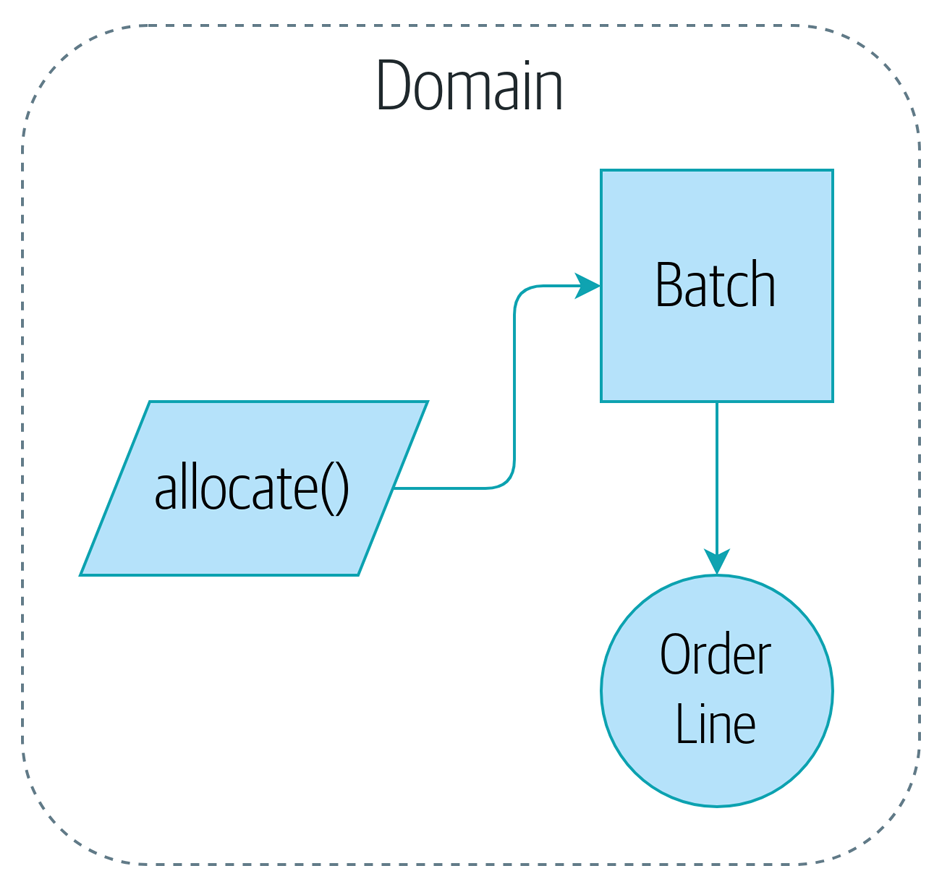
实体
当一个对象由其标识(而不是属性)区分时,这种对象称为实体(Entity)。
在权限中心, 用户, 管理员, 策略, 都有唯一的标志, 可以分门别类划分到各自域的实体
值对象
当一个对象用于对事务进行描述而没有唯一标识时,它被称作值对象(Value Object)。
权限中心中, 策略中的拓扑, 属性, 这些没有唯一标志的值, 就是值对象
Repository
数据存储的adapter, 以Entry为参数, 保存实体信息到存储引擎, 从数据库中加载数据为实体对象
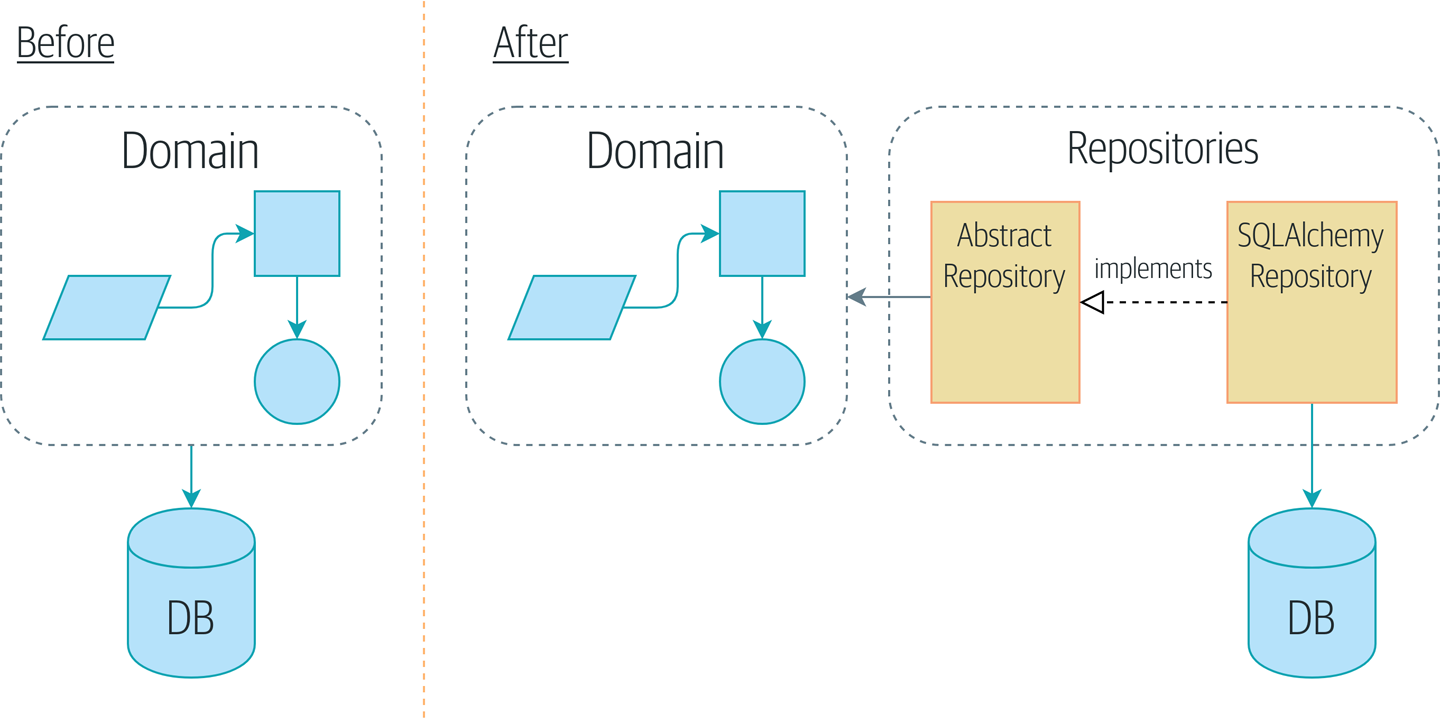
好处:
- 简单的接口, 解耦了对存储的依赖
- 方便进行单元测试, 通过Facke Repository
- 开考虑如何存储数据前, 专注于解决业务问题, 使得模型更加贴合实际问题
坏处:
- 增加了额外的代码逻辑, 提高的维护的成本
- 有一些逻辑可能ORM框架就已经支持了
Service
服务层, 领域模型的使用用例, 一些重要的领域行为或操作,可以归类为领域服务。它既不是实体,也不是值对象的范畴。
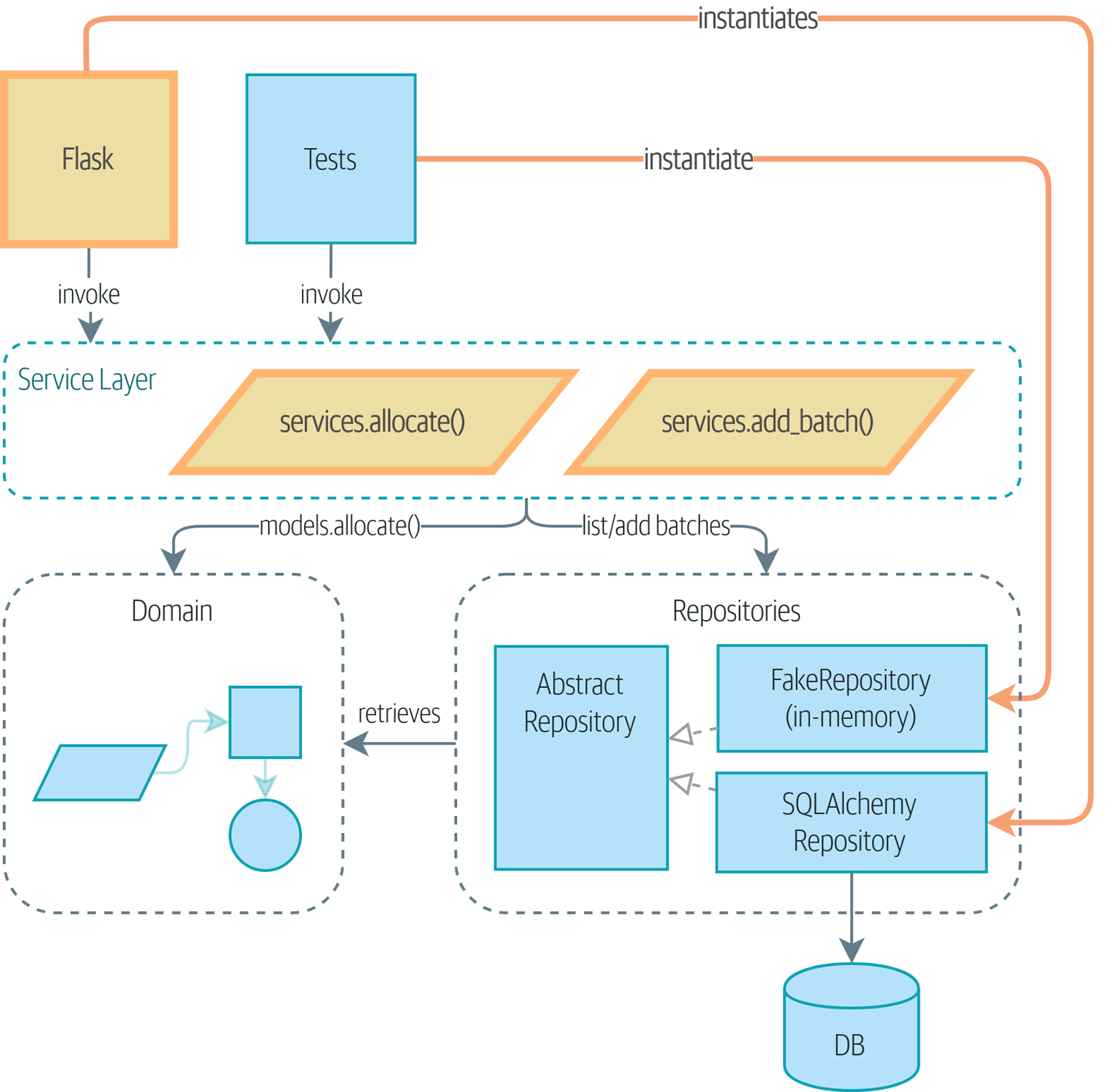
好处:
- 提供一个单一的地方放所以的用例
- 通过服务层来把领域模型隐藏在api后面, 方便对领域层做重构
- 把定制http相关的协议改变成了定制服务的协议, 接口只是服务层的派生
- 有了存储层后, 可以方便的使用Fake存储来做测试
坏处:
- 如果你的app是一个纯粹的web服务, MVC就可很好的处理用例了, 不需要增加多余复杂度
- 服务层是另外的一个抽象
- 服务层承载了太多的逻辑, 会导致领域层成为贫血模式
- 在采用服务层前, 需要理清控制面上的逻辑编排
- 把控制面的逻辑下沉到领域模型上, 可以得到胖模型, 瘦控制
Unit of Work
service层中直接对接了Repository, 处理了太多事务相关的逻辑, 通过UOW来封装事务的处理
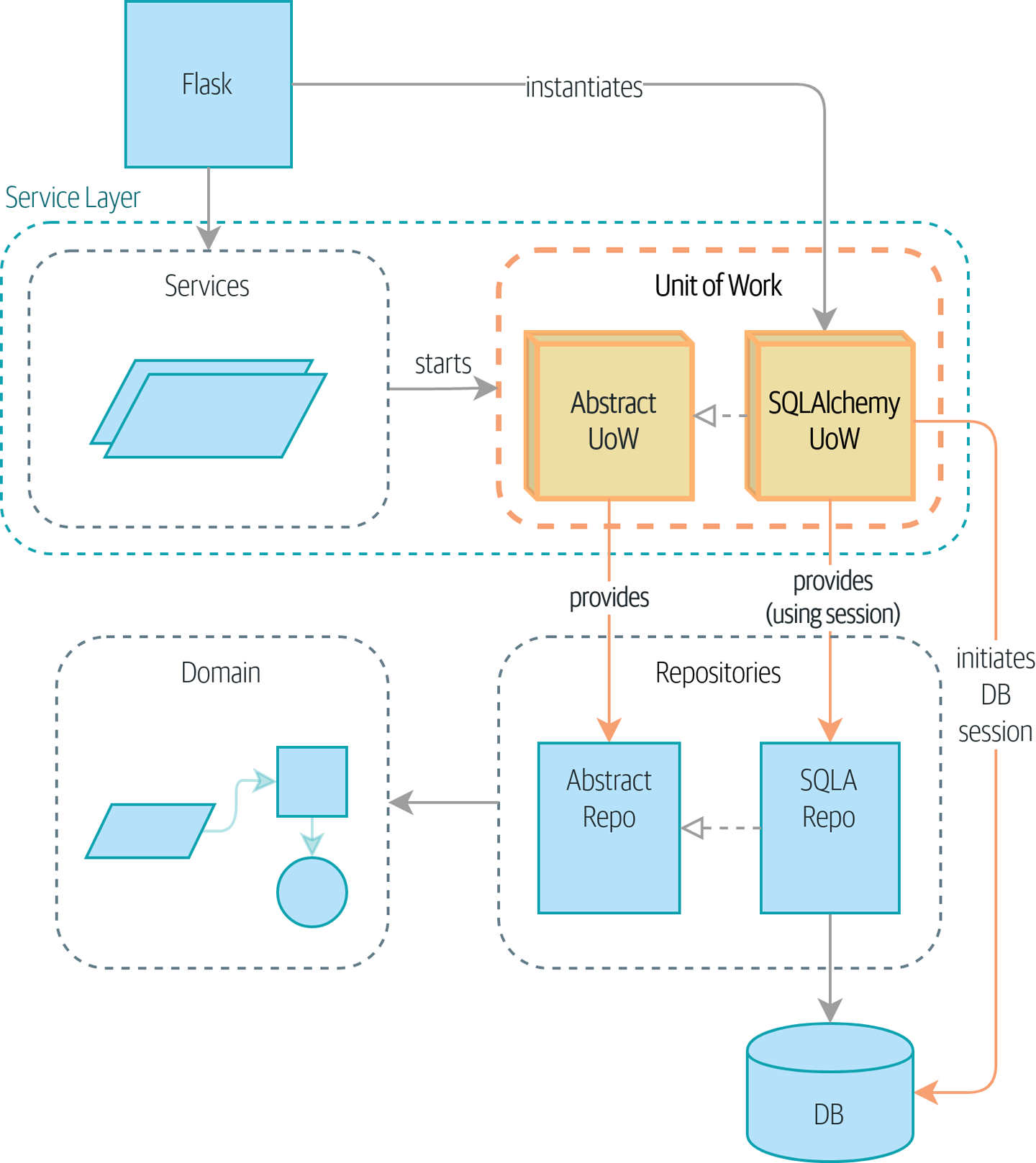
好处:
- 对于原子操作有一个更好的抽象, 通过上下文管理器直观的看到哪些逻辑组合在一起
- 对事务的开始与结束有了明确的定义
- 提供了实例化存储类的地方
- 帮助处理事件与消息总线
坏处:
- 可能ORM已经有类似的封装
- 看起来简单, 但是还要处理回滚, 多线程, 嵌条事务等情况
Aggregate
Aggregate(聚合)是一组相关对象的集合,作为一个整体被外界访问,聚合根(Aggregate Root)是这个聚合的根节点。
有了Service与UOA后, 往往会导致Service的逻辑复杂, 而领域模型上的逻辑非常简单, 甚至于没有相关的方法, 这就是所谓的贫血模式/失血模式, 这时候就需要一种新的抽象来承载领域模型上的相关逻辑, Aggregate
以权限中心为例, 每次操作的Policy并不是一个, 而是一批, 这时候就可以定义PolicyAggregate, 来把批量的Policy操作的方法封装在聚合之中
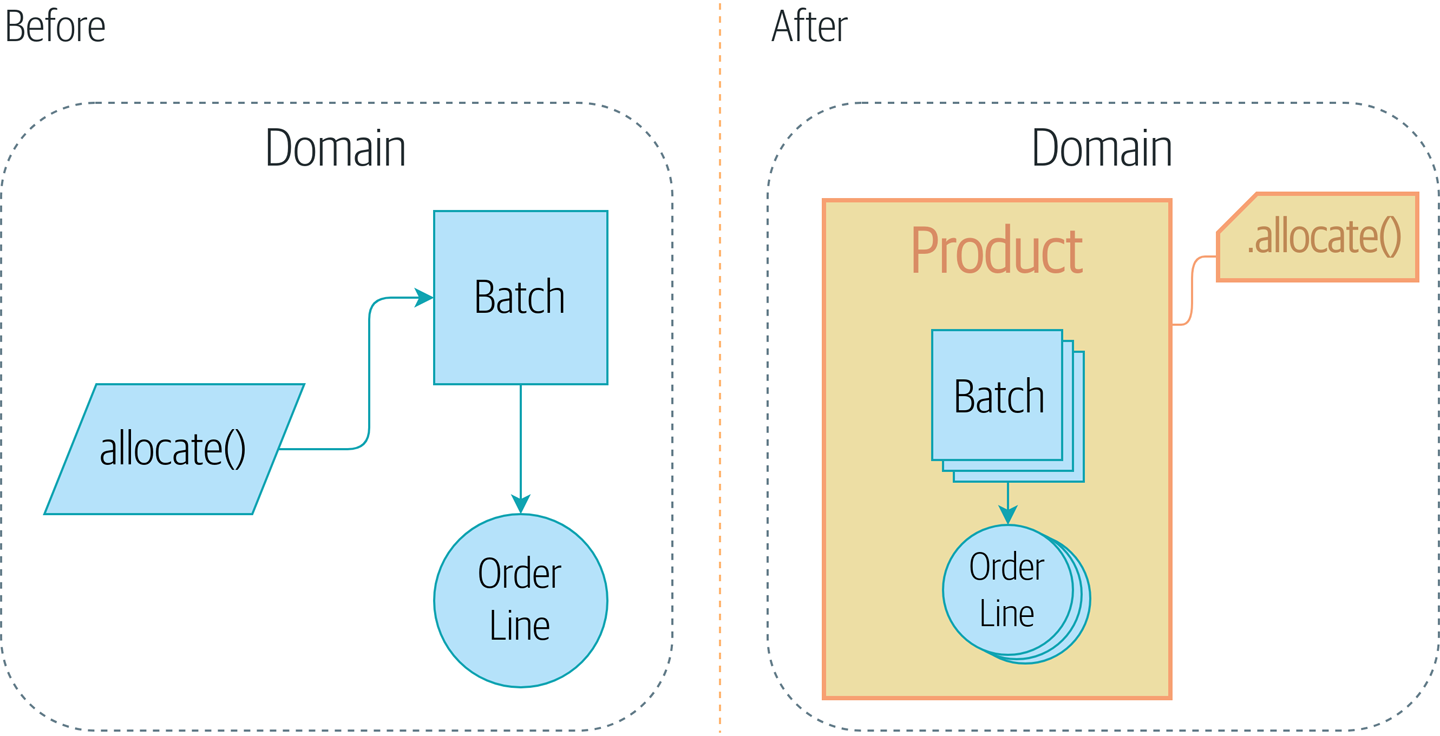
好处:
- 聚会可以定义出哪些模型是可以暴露, 那些不暴露
- 显示的定义界限上下文, 有助于提高ORM性能
- 由聚合来负责状态的变更, 更容易控制内部数据, 提供统一的出入口
坏处:
- 对于新开发者不友好, 需要多理解一个概念
- 严格定义聚合的单一职责, 对于思维的考研很大
- 不同聚合之间数据的最终一致可能很麻烦
Event Drive
领域事件是对领域内发生的活动进行的建模。
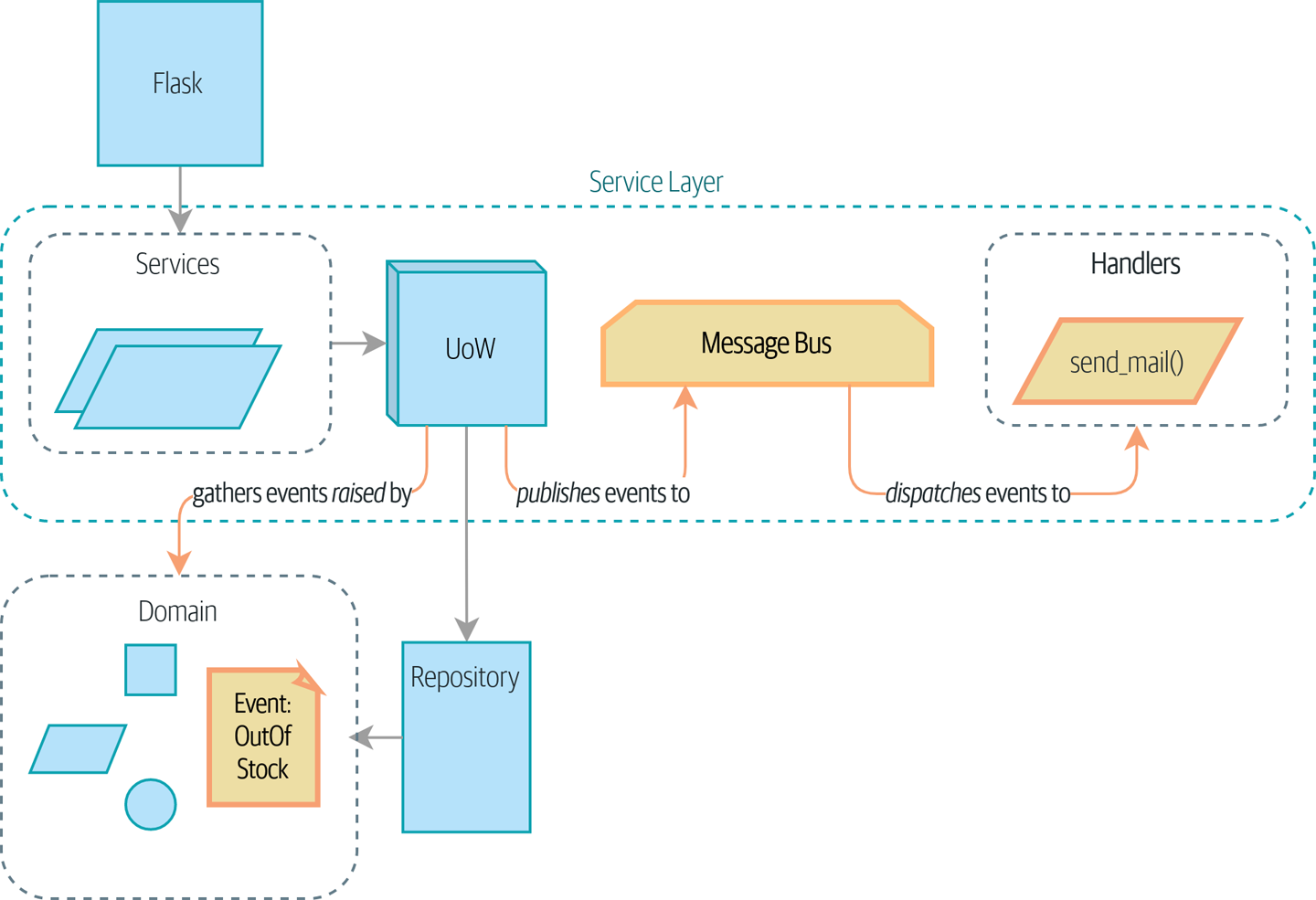
好处:
- 消息总线解耦了不同逻辑之间的耦合, 通过响应消息实现多种逻辑的处理
- 时间响应的处理与核心的领域逻辑得到隔离
- 领域时间实际上是现实问题的一种抽象, 可以跟领域语言有机的结合到一起
坏处:
- 消息总线隔离各种逻辑, 不方便梳理整体逻辑
- 要小心消息的循环依赖
完全的事件驱动
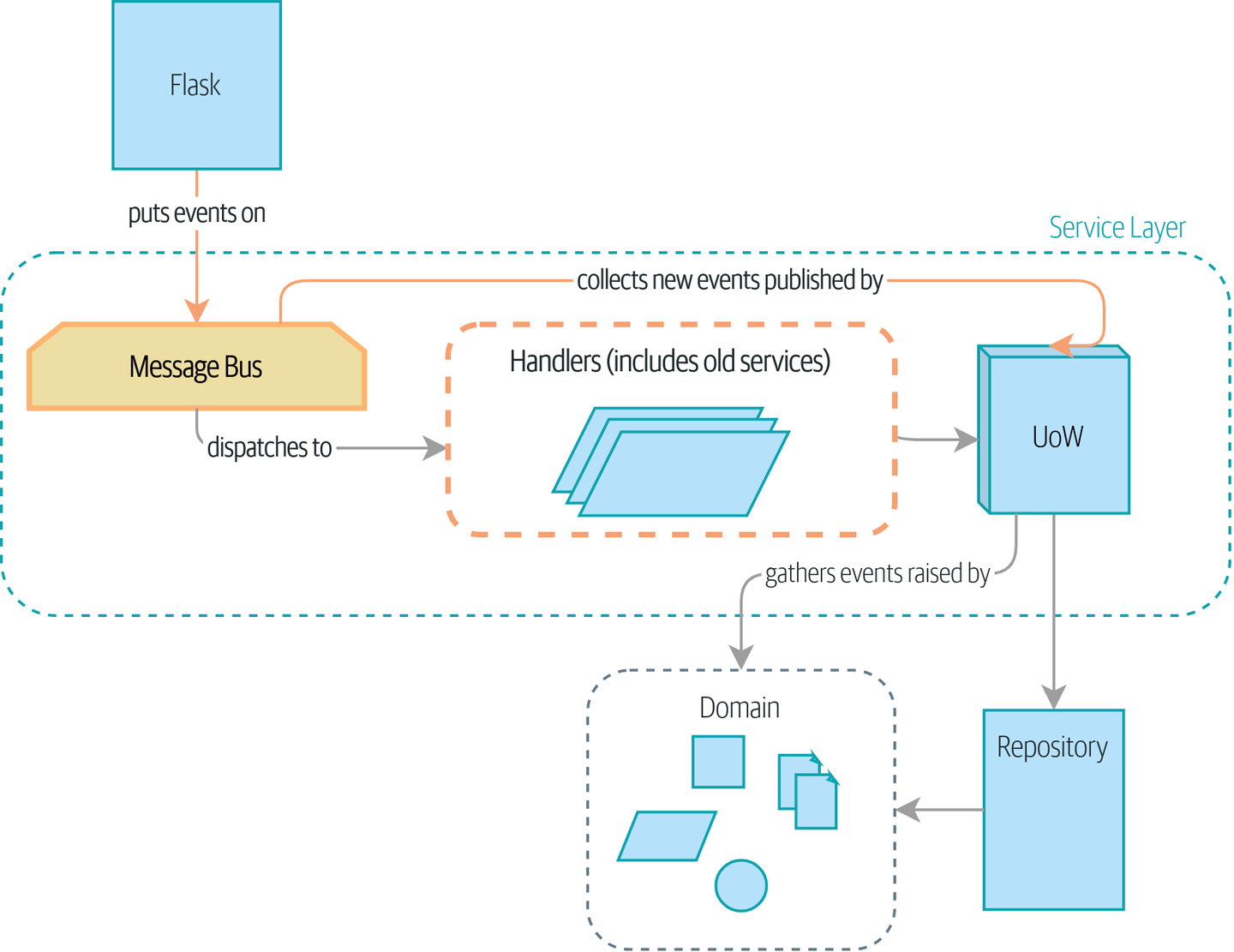
好处:
- handler与service变成了一个, 架构简化
- 事件对于api与handle的参数传递提供统一的结构
坏处:
- 对于web服务来说, 消息总线不是一个可以感知的过程, 异步逻辑不知道什么时候完成
- 事件对象与模型对象存在大量相同的字段, 修改时也要同时修改
引入命令模式:
好处:
- 区分出命令与事件, 可以清晰的定义出哪些是必须完成的, 哪些是额外的逻辑
- 命令名称相对于事件更明确
坏处:
- 命令与事件语义上的差异可能很小, 要小心区分
- 明确的处理失败与异常, 使得影响变小, 逻辑更加难理解, 需要增加更多监控
事件驱动的微服务:
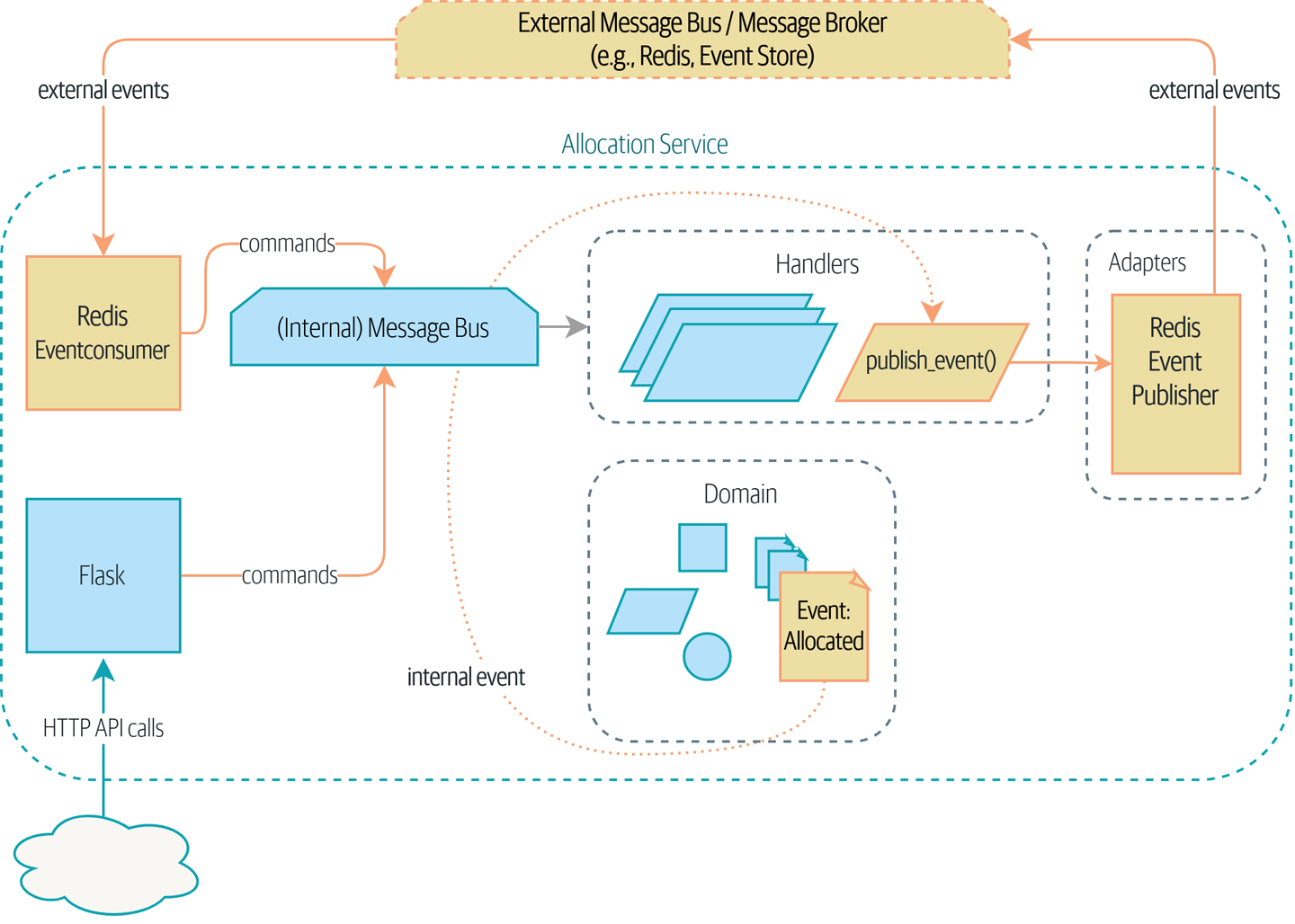
好处:
- 避免依赖大泥球
- 分离服务: 更新与新增单个服务更简单
坏处:
- 整理流程的信息很难直观看出来
- 需要理解最终一致性
- 消息的可靠性需要权衡: 至少一次还是最多一次
CQRS
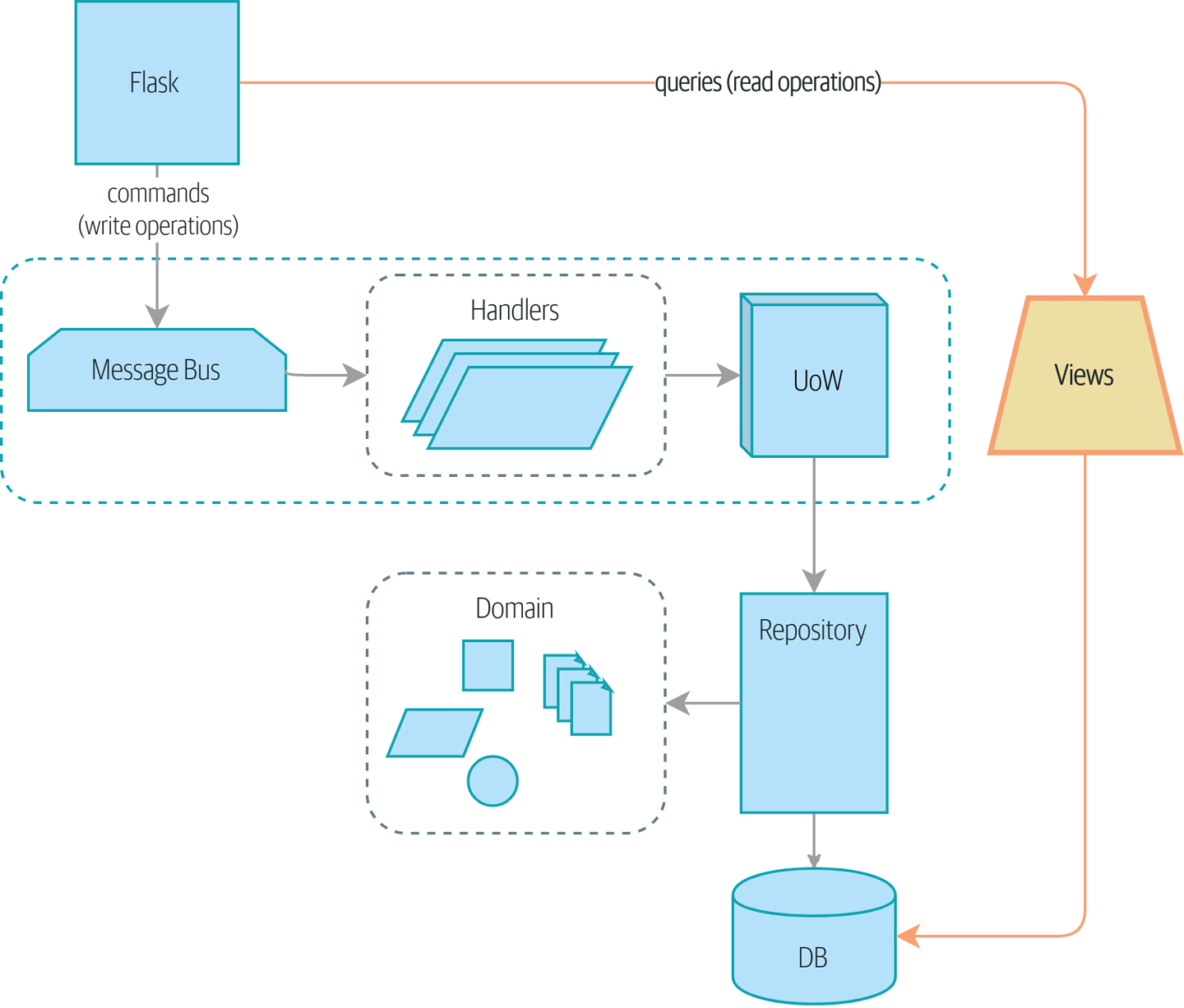
命令于查询分离
| 查询 | 命令 | |
|---|---|---|
| 行为 | 简单 | 负责业务逻辑 |
| 缓存 | 可缓存 | 不可缓存 |
| 一致性 | 可能延迟 | 事务一致 |
微服务
宏服务的问题
代码量变大: 模块之间没有严格的界限, 想要理解系统整体困难, 随着代码的增加复杂度增加, 变更的成本变高, 降低迭代速度
资源利用低效: 整体服务占用大量的内存, 不管其中模块是否被大量的使用, 占用所有的数据库连接, 不管有没有使用
带来可扩展的问题: 即使能实现横向的扩展, 但是开发的过程中由于团队的人员变多, 也会带来版本迭代上的冲突, 除非有很好的职责划分, 不同团队之间的沟通, 会带来效率的降低
部署困难: 每次部署都需要保证所有模块的正确性, 其中某个模块出问题, 会导致整个系统的崩溃
技术的限制: 在选定一种技术后, 整个系统的技术就被限制了, 比如Python, 想要更改会非常困难
bug影响: 一个模块的bug可能会影响到整个系统, 一个模块的资源占用过多, 也会影响到整个系统
微服务
模块之间松耦合
独立部署
每个微服务互相通信
为了提供整体的服务, 需要把微服务暴露成一个整体, 微服务隐藏在整体后面
优点:
微服务之间使用统一的通信协议通信, http-json, 更加通用一些, rpc更加高效
更好的资源利用率, 每个服务都是可控的, 按需分配资源
每个微服务都很小, 代码量少更简单, 重构更方便, 可以选择不同的技术栈
某些服务可以隐藏在微服务后面, 不对外提供, 更加安全
由于系统的独立, 一个服务的崩溃不会导致整体的崩溃
每个服务都是独立维护, 提高团队的开发效率
缺点:
迁移到微服务很困难, 需要付出大量的开发成本, 初期会带来很多混乱
微服务的会带来组织架构上的调整, 而一般公司的组织架构是很难改变的, 就会导致职责的分不清
学习曲线陡峭, 开发人员需要学习相关的开发模式, 需要开发运维相关的培训
调试更加困难
划分微服务本身很困难, 需要警惕多个独立服务合并到一个服务中, 这样就偏离的迁移微服务的初衷
违法对于团队配合会带来困难, 不同的团队会站在自己的角度思考, 沟通协调需要付出更多的成本
在整体功能与每个微服务的功能之间需要做平衡, 没有很好的配合, 团队之间会出现信息孤岛, 重复造轮子. 应该共享知识, 共享经验
敏捷开发的同时, 需要各个团队落地的文档就有要求了, 可以减少沟通, 但是增加额外的工作量
如果有对其它服务的依赖, 会增加请求的响应时间
总结
没有银弹, 没有完美的技术, 只有合适的技术.